
引言
编程语言从它的出现开始就在不断的发展,从机器码到汇编再到高级语言,编程的方法论也在不断的发展,在计算机出现至今的 70 多年的时间里,编程方式从写字节码,到面向过程,再到面向对象不断推进,而今天,各种的老牌、新式语言都加入了一个引领下个时代编码的编码风格:函数式编程。本文会主要使用 Java 语言,简要的谈谈我对函数式编程的理解。
函数式编程?啥玩意啊
函数式编程顾名思义,最主要的就是函数,它最开始就是一群数学家为了方便自己进行理论证明而建立的一套叫做『范畴论』的东西,后来发现这东西可以用来编程。在这里,函数就是一切,函数是构成程序的一切。纯函数式语言是没有变量的,一切都通过函数来进行操作。
假设有这么个场景:我开车去吃饭,用命令式和面向对象的方法的话,会变成如下情况:
class 人类 {
// ...
public void 开车(车类 车) {
this.xxx = xxx;
车.xxx = xxx;
}
}
class 车类 { ... }
class 饭类 { ... }
车类 车 = new 车类();
人类 我 = new 人类();
饭类 饭 = new 饭类();
我.开车(车);
我.吃饭(饭);
而函数式编程的话,会写成如下情况:
final 车类 车 = new 车类();
final 人类 我 = new 人类();
final 饭类 饭 = new 饭类();
// 定义函数
BiFunction<我类, 车类, 我类> 驾驶 = (m, c) -> {
// 对参数进行处理
...
// 构造返回结果
我类 驾车后的我 = new 我类();
return 驾车后的我;
}
// 定义函数
BiFunction<我类, 饭类, 我类> 吃饭 = (m, f) -> xxxxxx;
人类 驾车后的我 = 驾驶(我, 车);
人类 吃完饭的我 = 吃饭(驾车后的我, 饭);
这个简单的例子可以看到,在命令式的编程中,一直是在通过『我』来调用相关的方法,修改我和车的状态,而函数式的编程的会在每次调用函数后返回一个新的,变更了状态的『我』。这是为了确保函数没有副作用,一切修改/操作共享变量的行为都属于副作用。
函数式编程的函数和我们 C 语言等面向过程的语言中的函数有些许的不同,这里的函数是数学定义上的函数。
$$
f(x) = g(x)
$$
数学函数的意义在于,它表示的是数据结果的映射,传入一个指定的数,返回的是结果集上的另一个数。这样的函数带来的特性是:输入输出是稳定的,独立的。在任何位置执行该函数,都会得到确定的结果。就如同上述例子中,我们传入的是我和车,返回的是驾车后的我,(我和车) 和 (驾车后的我) 之间的对应关系,就是函数式编程的根基:『范畴』。
范畴论是数学的一门学科,以抽象的方法处理数学概念,将这些概念形式化成一组组的“物件”及“态射”。数学中许多重要的领域可以形式化为范畴。使用范畴论可以令这些领域中许多难理解、难捉摸的数学结论更容易叙述证明。
为啥要用函数式?
上面基本的介绍了函数式编程的一些来历,那么,为什么要使用函数式编程呢?有很多的原因,其中最重要的原因有如下三个:
并行处理的能力
函数式编程天生拥有并行处理的能力。在硬件发展碰到功耗墙后,多核处理器成为了绝对的主流。函数式编程相对于多线程编写的低门槛,也导致了当前函数式编程的流行。
为什么它能拥有天生的并行能力?因为函数式编程的概念是来源于数学上的,所以它是没有副作用且稳定的。每次调用都会返回一个新的对象继续进行操作,这确保了函数内外都是独立的状态,没有任何的副作用,再也没有并行的问题了。
是更高层次的抽象
函数式编程是更高层次的抽象。就如同垃圾回收一般,使用过拥有垃圾回收机制的语言,相信没人再会想要回到那个连数组都要手动分配空间的语言上。把控制权更多的交给语言/运行时,把时间花在更高层次的抽象上,多考虑怎样解决复杂的 业务场景,少去费心复杂的底层运作。
人生苦短,远离 malloc
这种高层次的抽象也带来了一种好处,如果运行时/函数底层逻辑升级,无需改动任何一行代码,程序就可以获得性能上的提升。
JVM 语言 Clojure 基础库中的 map 方法经过创造性的重写,获得了自动并行的能力,也就是说,所有 Clojure 开发者不需要动一行代码,就自动享受到了map 操作的性能提升。
更小的复用层次
在 Java 中,我们倾向于创建更多的数据结构,并将方法绑定在数据结构上,重载/重写它们的方法来解决不同的问题,但是这样很可能遇到一些冗余的问题。以数据库操作为例,在面向对象命令式编程的写法中,它会是这样的:
public void list() {
// 初始化操作
......;
实际数据处理逻辑();
// 释放资源操作
......;
}
诚然,我们可以通过 try...finally 的方式回收资源,但是这样的方式终究是不够通用,而且想要复用十分的麻烦。如果用函数式的写法:
public <T,R> void list(Function<T, R> doSomething) {
// 初始化操作
......;
doSomething.apply(data);
// 释放资源操作
......;
}
这样操作下来,处理数据的逻辑都被封装在了函数里,想要更换其他的处理方式也是传个参数的事,可见其复用性。
你说的都挺有道理,那么问题来了:咋写
因为 Java 8 中,函数已经可以作为变量出现了,所以首先要知道它怎么声明:
| 函数式接口名 | 函数接受啥 | 函数返回啥 | 函数咋调用 | 函数有啥用 |
|---|---|---|---|---|
Consumer<T> | 接受一个任意对象 | 返回空 | accept(obj) | 消费者,意思就是我把你传进来的东西消费了,吃了!一般用来把什么东西给输出/处理掉。 |
Function<T, R> | 接受一个任意对象 | 返回一个任意对象 | apply(obj) | 普通的函数,把你传进来的东西做一些你指定的操作/转换,然后返回转换后的对象 |
Predicate<T, Boolean> | 接受一个任意对象 | 返回一个布尔值 | test(obj) | 断定,把你传进来的东西抽取并判断,返回布尔值,一般用于 if 条件 |
Supplier<R> | 啥也不接受 | 返回一个任意对象 | get() | 提供者,根据给定的逻辑生成新对象的方法,多用于提供某种对象或生成无限的对象 |
内置的函数式接口大抵就这么几个类别,其余的也是扩展了入参数量的。
每个函数接口都带泛型,可以根据需要传入的参数来给定。其实这些接口就相当于给各种参数列表和返回值的函数起了个别名,具体到底传什么,请根据泛型来确定。举个栗子:
List<Object> list = new ArrayList<>();
list.stream()
// map 方法接受一个 Function<T, R>
.map(item -> item.doSomethings())
// filter 方法接受一个 Predicate<T, Boolean>
.filter(item -> true)
// forEach 方法接受一个 Consumer<T>
.forEach(item -> System.out.prin);
有了接口名,我们怎么给它赋值呢?有两种方法
1. Lambda 表达式
一个 lambda 表达式就是一个函数,它在底层是通过一条 Invoke Dynamic 指令进行调用的。有三个部分
():参数列表,被传入的参数,如果只有一个参数,括号可以省略->:lambda 的关键字,有它才能是一个 lambda{}:lambda 函数体,编写实际的函数体,可以返回值- 如果函数体只有一行,可以省略大括号
- 如果省略了大括号,则该行函数体的返回值为 lambda 的返回值
// 1. lambda 表达式
() -> {} // 这就是一个 Lambda
// 2. 一个参数的 lambda
object -> {}
// 3. 一行函数体的 lambda
object -> object.xxx();
// 4. 多行带返回值的 lambda
object -> {
xxx(object);
object.xxx();
return object;
}
// 5. lambda 赋值
Function<Object, Object> lambda = object -> object.xxx();
有了 Lambda,我们就有了随处定义函数的能力了。
2. 方法引用
方法引用就是把一个方法搞成函数式变量的办法
方法引用的操作符:对象/类::方法名,使用对象和类需要
class xxx {
public static void main(String[] args) {
Consumer<Object> con = xxx::myFunction;
Object o = new Object();
con.accept(o);
}
public static void myFunction(Object o) {
// 做一些操作
......;
}
}
方法引用相比 Lambda 的优势在于
- 可以给 Lambda 起一个好听的名字,毕竟
this::getObjectName要比obj -> obj.name直观许多。 - 复用起来更加方便。
更详细的操作推荐去看图灵社区出版的 Java实战(第2版)
流式操作
跟随函数式一起引入 Java8 的另一套关键系统就是对数据的流式操作,之前也有谈到函数式编程鼓励使用有限种类的数据结构如 List; Map; Set 和可变的操作方式对数据进行处理,所以引入了MapReduce-百度百科对流进行操作。关于 Java 中的各种流式操作的含义以及用法,请参考我同事的博客:Lambda学习 - LanDay。
流式操作就是一个很明显的由运行时帮我们对代码逻辑和执行方式优化的典型,有了流式操作,再也不用纠结于每次循环的控制条件,如何操作共享变量,我们只需要定义好要传入的函数,一切就能够运行的很好。而且通过流式操作的拆分,每次操作都可以进行复用。世界变得更加美好了。
因为流式操作的一些特性,所以我们的程序可能会出现写不明白,调试难调等不少问题,但是流式所带来的优势和灵活性,值得我们去学习和使用的。如果更多的了解函数式,在每次报错的时候都会大概有所眉目,需要做到的是哪些地方没有遵循范式要心里有数。
确保函数没有副作用
流式编程和顺序编程最明显的一点区别就是:由库代码实现帮你选择和调整流中操作的执行顺序:
// 生成一个 [1, 100) 的流
IntStream.range(1, 100)
// 过滤所有的偶数
.filter(i -> i % 2 == 0)
// 每个数乘 2
.map(i -> i * 2)
// 截取前 10 个
.limit(10)
// 求和
.sum();
// ------- 上述代码与下列代码等价 ------
IntStream.range(1, 100)
// 截取前 10 个
.limit(10)
// 过滤所有的偶数
.filter(i -> i % 2 == 0)
// 每个数乘 2
.map(i -> i * 2)
// 求和
.sum();
这样的操作很酷炫,但是稍有疏忽也可能会出现 Bug。比如在某个 lambda 中操作共享变量,更改变量状态和值等操作,导致整个流处理不符合预期甚至报错。
所以我们要尽可能的保证传给流的操作是无副作用的。之前所强调的纯函数,就是函数式代码稳定运行,并行操作的基石。如果你的流处理发生了错误,一定要尽最大努力,保证函数无副作用,这样才符合函数式的思想,更多的复用。
流式编程和传统命令式的比较
那么,相比于命令式的顺序编程,函数式的优势体现在哪?我们使用一个具体的例子来进行说明:
现有两个 List,他们的指针一一对应,现需要根据其中一个 List 同步进行排序
命令式解法
public class CompareWithStream {
static final List<String> sList;
// 根据这个 List 排序
static final List<Integer> sortNumberList;
static {
// 初始化一下要用到的变量
String[] strings = {"a", "b", "c", "d", "e", "q", "f"};
Integer[] sortNumber = {5, 6, 2, 3, 1, 7, 4};
sList = List.of(strings);
sortNumberList = List.of(sortNumber);
}
public static void main(String[] args) {
// 使用命令式的排序方法
commandProgramming();
}
// 方法体
public static void commandProgramming() {
System.out.println("------------- 使用命令式编程 ---------------");
// 复制一份 List
List<String> result = new ArrayList<>(sList);
List<Integer> resultInt = new ArrayList<>(sortNumberList);
// 手写一个冒泡排序算法
for (int i = 0; i < sortNumberList.size() - 1; i++) {
for (int j = 0; j < sortNumberList.size() - 1 - i; j++) {
if (resultInt.get(j) > resultInt.get(j + 1)) {
// 根据一个 List 的值同时交换两个 List 中的值
int temp = resultInt.get(j);
String temps = result.get(j);
resultInt.set(j, resultInt.get(j + 1));
result.set(j, result.get(j + 1));
resultInt.set(j + 1, temp);
result.set(j+1, temps);
}
}
}
// 输出一下子
for (String s : result) {
System.out.println(s);
}
for (Integer integer : resultInt) {
System.out.println(integer);
}
}
博主的水平不高,手写冒泡算法还得问问度娘,实力比较强的可以换成插入/快速/堆排序。这样磕磕绊绊写出了一个排序的方法,看看时间复杂度,哦哦,最坏O(N^2),空间呢?挺好,就这俩数组在交换,O(1);但是:引入了一个自己写的算法,这个算法有没有 Bug?百度上搜的,不知道。那如果数组变长了,还能稳定运行么?我的 ArrayList 变成链表了,还能行么?这些问题先放放,再看看流式编程的解法
流式编程解法
public class CompareWithStream {
// 声明和初始化与上面相同
......;
public static void main(String[] args) {
// 使用命令式的排序方法
streamProgramming();
}
public static void streamProgramming() {
System.out.println("------------- 使用流式编程 ---------------");
// 创建一个内部类,将两个 List 的弱关联变为强关联
// 使用 Lombok 省去一些没用的模板代码
@AllArgsConstructor
@Getter
@ToString
class Item {
String s;
Integer n;
}
// 创建一个内部类用来收集最后的执行结果
// 因为 Stream 只能返回一个对象,所以像这种要返回两个 List 的操作,需要构造一个结构来存储
class Result {
final List<String> stringList = new ArrayList<>();
final List<Integer> integerList = new ArrayList<>();
}
// 正式开始进行操作
// 1. 通过 IntStream 生成 0 到 size 的下标
Result result = IntStream.range(0, sortNumberList.size())
// 2. 将两个 List 中的 i 号元素强关联,转换、生成 Item 对象
.mapToObj(i -> new Item(sList.get(i), sortNumberList.get(i)))
// 3. 调用排序方法,传入比较两个元素的方法(此处通过比较 Item.n 来实现)
.sorted(Comparator.comparing(Item::getN))
// 4. 收集最终的处理结果,映射为 Result 对象
// 该方法传入三个参数 1. 一个 Result 对象的构造方法,用来构造一个 Result 对象
// 2. 为 Result 对象添加元素的方法,这里是给每个其中的 List add Item 中的对象
// 3. 两个 Result 对象的合并方法,如果流是并行的,就会涉及到两个 Result 对象的合并
.collect(Result::new,
(result1, item) -> {
result1.stringList.add(item.getS());
result1.integerList.add(item.getN());
}, (m, n) -> {
m.stringList.addAll(n.stringList);
m.integerList.addAll(n.integerList);
});
// 打印一下子
result.stringList.forEach(System.out::println);
result.integerList.forEach(System.out::println);
}
}
看着很多,其实,一共就三个操作:
- 变换
- 排序
- 收集
这就是流式操作的方式,如果按性能来的话,map() 操作循环了整个列表一次,sort() 方法为了排序,循环了整个列表 n 次,collect() 方法为了将结果映射到目标,循环了一次列表。时间复杂度?那是啥,我只觉得我写的好爽。但是,在流操作中,不用去管什么共享变量,不用去交换数组元素,只是在开始构建了几个数据结构。
上面的代码还是略显复杂,如果再抽象一下的话,会变为 map().sort().collect() ,三步操作,让流帮你干任何事。
一个假设
上面演示了流式操作和传统的命令式操作的区别,屏蔽了不少的底层细节。我们在初学 Java 的时候,没少被教导过抽象的问题。
现在,假设我们的需求发生变更了,字母 e 因为不符合需求,需要被剔除掉。我们还是先来看看命令式的解法。
public static void commandProgrammingWithoutE() {
System.out.println("------------- 使用命令式编程: 没有e ---------------");
// 复制一份 List
List<String> result = new ArrayList<>(sList);
List<Integer> resultInt = new ArrayList<>(sortNumberList);
int eIndex;
// 把 e 筛掉
do {
eIndex = result.indexOf("e");
if (eIndex >= 0) {
result.remove(eIndex);
resultInt.remove(eIndex);
}
} while (eIndex >= 0);
// 手写一个冒泡排序算法
for (int i = 0; i < resultInt.size() - 1; i++) {
for (int j = 0; j < resultInt.size() - 1 - i; j++) {
if (resultInt.get(j) > resultInt.get(j + 1)) {
// 根据一个 List 的值同时交换两个 List 中的值
int temp = resultInt.get(j);
String temps = result.get(j);
resultInt.set(j, resultInt.get(j + 1));
result.set(j, result.get(j + 1));
resultInt.set(j + 1, temp);
result.set(j+1, temps);
}
}
}
// 输出一下子
for (String s : result) {
System.out.println(s);
}
for (Integer integer : resultInt) {
System.out.println(integer);
}
}
可以看到。。把 e 筛掉又引入了一个 do-while 循环。如果要再把 f 筛掉, g 筛掉,下标为 15 的筛掉呢?可怕。。。
那么我们来看看流式操作是怎么做的:
public static void streamProgrammingWithoutE() {
System.out.println("------------- 使用流式编程: 没有 e ---------------");
@AllArgsConstructor
@Getter
@ToString
class Item {
String s;
Integer n;
}
class Result {
final List<String> stringList = new ArrayList<>();
final List<Integer> integerList = new ArrayList<>();
}
// 正式开始进行操作
Result result = IntStream.range(0, sortNumberList.size())
// 筛掉 e
.filter(item -> !"e".equals(item.s))
.mapToObj(i -> new Item(sList.get(i), sortNumberList.get(i)))
.sorted(Comparator.comparing(Item::getN))
.collect(Result::new,
(result1, item) -> {
result1.stringList.add(item.getS());
result1.integerList.add(item.getN());
}, (m, n) -> {
m.stringList.addAll(n.stringList);
m.integerList.addAll(n.integerList);
});
// 打印一下子
result.stringList.forEach(System.out::println);
result.integerList.forEach(System.out::println);
}
可以看到:一句话,我们就把 e 给筛走了 filter(item -> !"e".equals(item.s)) 。这还不是程序员的福音么?
需求任他变,
流上加操作。
千变又万化,
造福千万家。
并行化
并行化三个字,我们听到想到的是什么?第一印象肯定是:卧槽能不用就不用。乐观锁悲观锁,自旋锁和死锁,光是这些锁的概念就能列出来一大堆,估计是无论如何都谈不上快乐的。管理线程间的共享变量,锁定哪个信号量等等,每个问题都让人头秃。但是现在流的出现,可以在一定程度上降低很多并行的门槛。
首先,函数式编程是要尽可能建立在函数无副作用的基础上的,那就说明该函数和时间已经脱钩了。无论是顺序、倒序、乱序执行都没有任何问题,这就有了并行执行的天然土壤。函数式编程并行的基础就是在每个函数都无副作用的基础上来的。通过每次输入一个元素/序列,并返回一个全新的、确定且稳定元素/序列保证结果和被操作元素不被篡改,并发并行都不在话下。
不过纯函数多多少少还是有点少,也有些和 Java 语言的支持有一定的关系。
Java 在 8 之后的版本中提供了针对两种不同情况的并行操作
1. 流
流的设计使得它天生就是一种可以并行的东西。每个(无状态)操作只和上一个操作的结果相关联,那么我们只要把流进行拆分,执行后合并计算结果
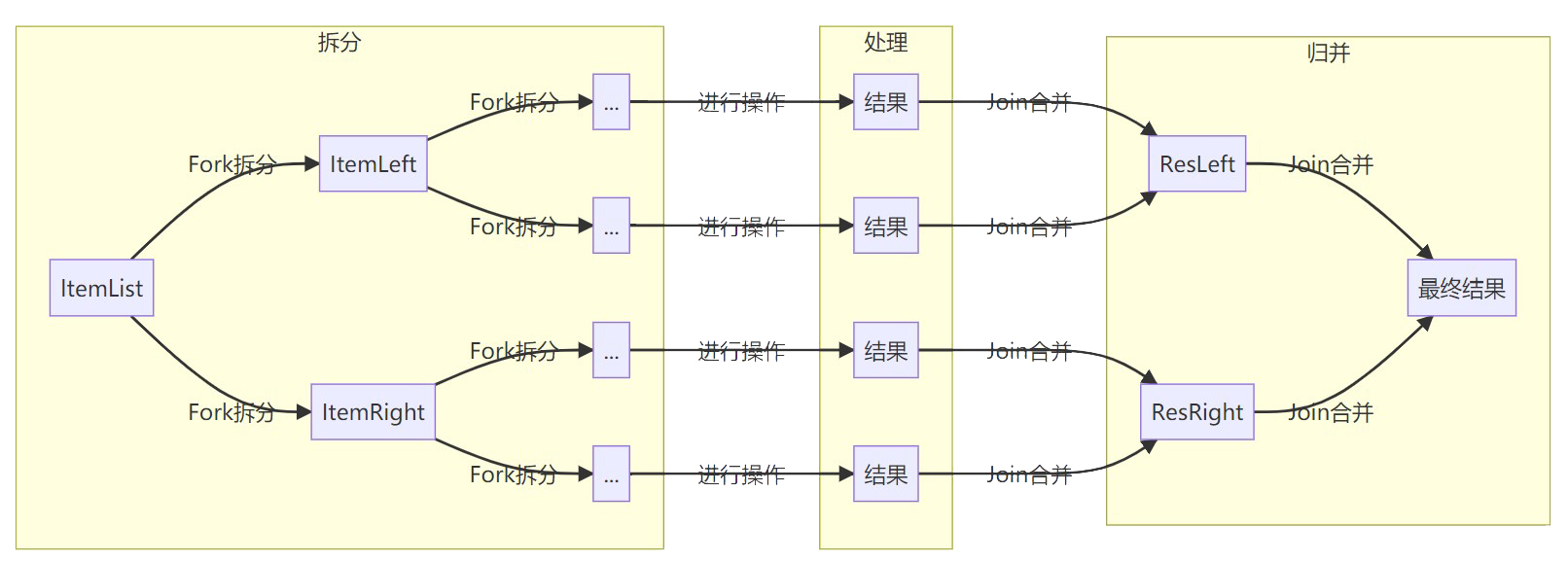
而如此复杂的操作,需要怎么来表达呢?只要一个方法,直接插火箭,还是 8 管的
collections.parallelStream() 或者 stream.parallel()
方便快捷~只要严格按照函数式的要求,不会有任何问题的!
2. 异步
Java 在 8 之前就已经有了异步的操作,但是 Java 8 中 CompleteableFuture 的出现,让异步操作更加得心应手
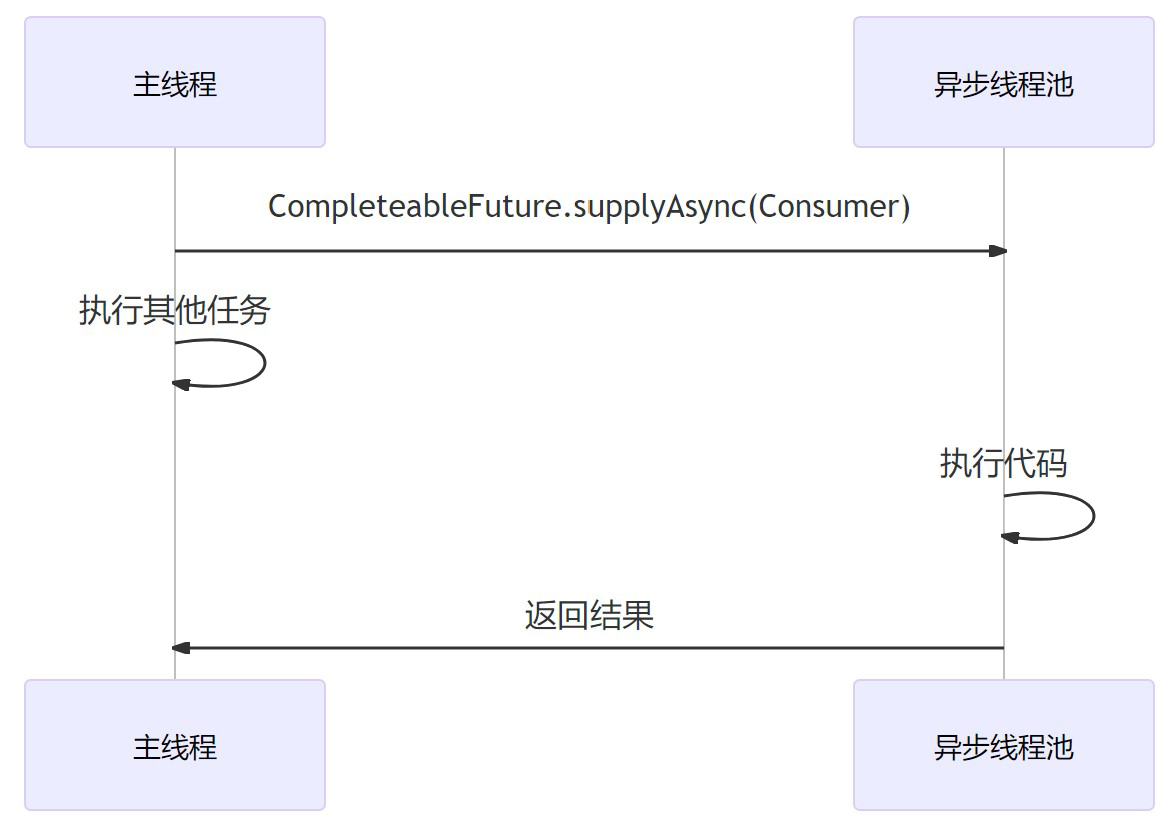
也是简简单单就在异步线程池中执行结束,在主线程中等待就行
总结
因为函数式的引入,可以看到并行化如同拿起杯子喝水一样简单。
纯函数式的优势
Java 并不是一个纯函数式的语言,所以它与一些纯函数式的语言还是有一些差别的,这里我们管中窥豹,列举一些纯函数式编程相对于 Java 的优势,来更加的理解纯函数式的好处:
1. 完全的递归支持
Java 的递归用过的都知道,会有爆栈的问题,那是因为在 Java 中没有尾递归优化,甚至到了 Java 17 还没有实现。感觉这个特性已经躺在了计划表上十几年了。我们来列举下递归能带来哪些好处
1. 直观
如果还能回忆起大学时期的算法课,那么你一定能记得,很多分治算法的递归写法都要比迭代写法好写的多,也好理解的多,往往简单的一个递归,翻译成迭代就会增加一大堆晦涩难懂的迭代代码,引入好几个状态变量。。。如果递归没有副作用,你还会选择迭代么?
2. 抽象
不可否认,递归是更高层次的抽象,将迭代细节给隐藏并转换成易懂的用法,更抽象的写法往往会使得程序更加的灵活多变
3. 转交控制权
递归将控制权转交给了运行时,由运行时管理代码的执行,返回值的操作和回收等。正如上面所说,将控制权转交给运行时,代表着可以解放双手,并且随着运行时的升级提升代码的效率等。
没有尾递归优化, Java 永远可能会遇到爆栈的问题。那我们也不能很放心的使用递归了。。
2. 函数执行结果的记忆
在函数式的语言中,提供了这么一个机制:将函数每次的执行结果缓存,有了这个机制,调用同一个函数时,如果有相同的入参,那么返回值也一定是确定的。这个特性源于纯函数的特性,即输入和输出结果是稳定的。你可能会觉得,我自己也能管理这些缓存,就是费点功夫嘛,但是正如上面所说的,由语言和运行时管理的缓存,它不比手动管理的好么?
想想看,每个函数的执行结果都不会被浪费,最大限度的减少程序的计算量,全自动的管理方法执行的缓存,那是一件多么酷炫的事啊。
要注意些啥?
读到这里你一定对函数式编程有了一定的了解,它也不是那么的遥不可及,甚至可以让你少做很多的工作,所以,从现在开始,拥抱函数式编程吧!
且慢:
在尝试函数式编程时,一定要注意在使用并发/多线程操作时,留意函数到底有没有副作用!到时候一个不小心,并发操作了,那就完了!必要时把多线程那些各种锁,都给带着!宁可慢不能错!
后记
这篇博客到这里就结束了,算起来这篇文章也磕磕绊绊写了有快一个月了,主要还是工作繁忙回家只想摆烂。不过好在还是找了个机会结了个尾。这篇可能是我写到目前最长的一篇博客了。Java 8 是我很喜欢的一个 Java 版本,它让 Java 变得更简洁,更现代了,这篇博客也没有踩谁捧谁的意思。函数式编程是个很大的话题,这次我只是尽可能的讲了讲函数式编程是什么,能为程序带来什么。作为一个 SICP 没有看完的新生代农民工,肯定有些理解不到位,比喻不恰当的地方,所以请看到博客的各位,如果有纰漏还请不吝赐教。